
Co sprawia, że korzystanie z bibliotek firm trzecich jest w Metapack bezpieczne?

Używanie zewnętrznych bibliotek w ramach wytwarzania oprogramowania jest zupełnie naturalnym procesem w każdej firmie czy projekcie. Należy je jednak opatrzyć szczególną troską i kontrolą. Dowiedz się, jak robimy to w Metapack.
Autor:

Piotr,
Software Development Team Leader
Używanie zewnętrznych bibliotek w ramach wytwarzania oprogramowania jest zupełnie naturalnym procesem w każdej firmie czy projekcie. Wiadomo – nikt nie chce wynajdywać koła na nowo, a wykorzystanie bibliotek firm trzecich pozwala także zaoszczędzić czas i energię na budowanie nowych rozwiązań w dziedzinach, w których czujemy się ekspertami. Praktycznie w każdym projekcie, nieważne w jakiej technologii jest on zrealizowany, moglibyśmy spisać długą listę nugetów, pakietów, npm-ów, gem-ów, które realizują pewne generyczne funkcjonalności (parsery, loggery, komponenty graficzne, całe frameworki programistyczne… można by wymieniać i wymieniać.
Wykorzystywane biblioteki zewnętrzne należy opatrzyć jednak szczególną troską i kontrolą. O odpowiednim opakowaniu ich przy pomocy dodatkowej warstwy abstrakcji nie będę tu wspominał, natomiast warto poruszyć inny ważny temat (o ile nie ważniejszy), mianowicie bezpieczeństwo ich użycia. O jakie bezpieczeństwo chodzi? Jakie zagrożenia mogą czyhać na dewelopera aplikacji,nieważne, czy projektu studenckiego, małej aplikacji komercyjnej, czy dużego serwisu enterprise?
Niezależnie jakich bibliotek zewnętrznych używamy – musimy zawsze zadać sobie dwa podstawowe pytania: kto jest jej autorem i na jakich zasadach mogę jej użyć (czy jest darmowa, czy płatna, ma otwarty, czy zamknięty kod).
Rozwijając te dwie kwestie możemy uszczegółowić te pytania: czy twórcy biblioteki dbają o jej bezpieczeństwo i czy biblioteka posiada podatności na znane klasy luk bezpieczeństwa oraz na jakiej licencji biblioteka jest udostępniana.
Ma to mniejsze znaczenie, jeśli realizujemy projekt studencki (chociaż warto pielęgnować dobre praktyki od samego początku), ale wykorzystanie biblioteki, która posiada znane podatności albo nie pochodzi z wiarygodnego źródła w dużych projektach komercyjnych, przypomina trochę spacer po polu minowym. W dobie wszelkich restrykcji związanych z bezpieczeństwem danych (GDPR), ransomware, czy wszechobecnego phishingu użytkowników – takie postępowanie może narazić firmę na ogromne koszty związane z karami, przywracaniem infrastruktury czy odbudową reputacji. Kwestia licencji, na których udostępniana jest dana biblioteka zewnętrzna, również nie jest bez znaczenia. Konia z rzędem temu, kto obudzony w środku nocy na wyrywki jest w stanie powiedzieć, na jakich zasadach możemy użyć danej biblioteki open-source (wszak są różne rodzaje licencji) oraz czy nieopatrzne użycie nie niesie za sobą pewnych konsekwencji np. biblioteka jest darmowa do użytku domowego, ale już płatna do komercyjnego albo wymaga udostępnienia źródeł aplikacji, która jej używa.
Jak się domyślacie w dużej firmie dużym wyzwaniem jest utrzymanie kontroli nad kwestiami opisywanymi w poprzednich akapitach. Najlepiej do tego wykorzystać pewien… (a jakże!) zasób zewnętrzny, który zrobi to po części za nas, ale co najważniejsze – jest specjalizowany w tej dziedzinie i zrealizuje oczekiwaną przez nas funkcjonalność na najwyższym poziomie. Część z problemów pomagają rozwiązać narzędzia klasy Software Composition Analysis (podklasa narzędzi Application Security Testing).

Źródło: https://resources.whitesourcesoftware.com/security/ast-application-security-testing dostęp z 03/02/2021
Nie zapewnią nam one stuprocentowej gwarancji i nie są panaceum na wszelkie bolączki związane z bezpieczeństwem i licencjami bibliotek, ale na pewno pozwalają nam poczuć się bardziej komfortowo, jeśli chodzi o ten aspekt wytwarzania oprogramowania. Jak używamy ich w Metapack?
WhiteSource – bo tej z usługi korzystamy w Metapack – pomaga nam właśnie w ogarnięciu problemów związanych z ryzykiem wykorzystania bibliotek open-source w naszych projektach.
Odkąd stosujemy zupełnie nowe podejście do tworzenia architektury naszych aplikacji (rozbicie monolitu, architektura mikroserwisów), możemy dość prosto zintegrować to narzędzie. Obecnie w firmie wdrażana jest idea DevSecOps, która m.in. zakłada przesunięcie odpowiedzialności za bezpieczeństwo „w lewo” (czyli blisko, jak najbliżej początku etapu developmentu danego projektu czy pojedynczej funkcjonalności). Za „security” odpowiedzialny jest zespół deweloperski, który dany komponent realizuje, a nie „mityczny” zespół ekspertów bezpieczeństwa, cała firma, albo… nikt.
Skaner WhiteSource wpięty jest w process Continuous Integration/Continous Deployment i analizuje poszczególne wpięcia kodu do repozytorium już na etapie jego pusha do mastera oraz (w zależności od zespołu i znalezionych problemów) alertuje w odpowiedni sposób, że coś jest nie tak (blokując dalsze przetwarzanie pipelinów CI/CD lub zgłaszając alert na platformę zarządzającą incydentami – PagerDuty). To duża różnica porównując z audytami bezpieczeństwa raz na przysłowiowy ruski rok, nieprawdaż?
Narzędzie WhiteSource podczas przeprowadzania skanowania kodu źródłowego w pierwszym etapie wykrywa użycie zewnętrznych komponentów open-source (zarówno użytych bezpośrednio jak i poprzez dependencje w innych bibliotekach).
Posiada do tego celu specjalnie przygotowaną i aktualizowaną na bieżąco bazę bibliotek. Następnie analizuje licencje danego komponentu, jej ograniczenia w użytkowaniu oraz konfrontuje je z polityką licencji dla danej organizacji.
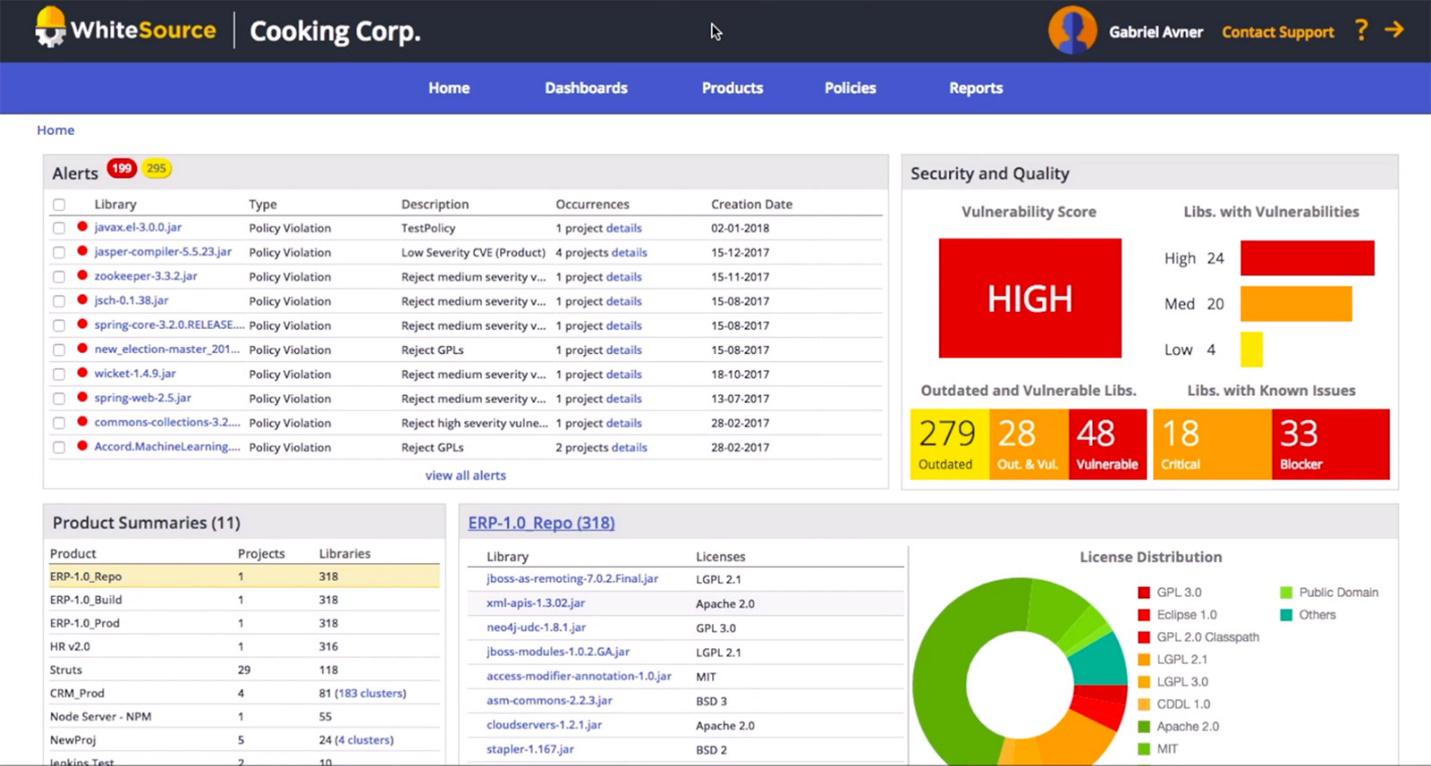
Jednocześnie analizuje znane podatności bezpieczeństwa i raportuje je, a także wyświetla rekomendacje, czy i w jakiej wersji zostały poprawione. Niezależnie od tego WhiteSource informuje nas po prostu o kolejnej, nowej wersji używanej biblioteki. Niedawno w Metapack zintegrowaliśmy także skanowanie kontenerów dockera i analizę warstw bazowych w celu szukania w nich znanych podatności.
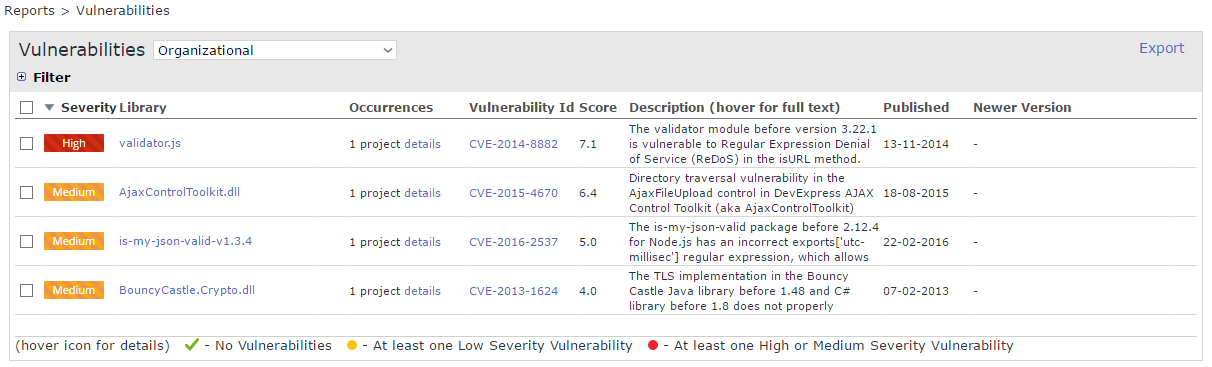
Zintegrowanie narzędzia klasy SCA, jakim jest WhiteSource, do pipelinów CI/CD w Metapack z pewnością nie jest sposobem na rozwiązanie wszelkich bolączek z bezpieczeństwem wytwarzanego oprogramowania. Dopiero wdrożenie całego łańcucha narzędzi i ich kombinacji może zredukować znacząco ryzyko.
Z mojego doświadczenia wynika, że utrzymywanie zewnętrznego źródła informacji o bibliotekach, które posiada aplikacja oraz sam algorytm wykrywania i analizy ryzyka jest wielkim ułatwieniem i pomocą dla dewelopera, który może pogubić się w gąszczu licencji, podatności, polityk bezpieczeństwa.
Wpięcie całego mechanizmu w proces CI/CD dodatkowo „uszczelnia” całą integrację przed wpięciem potencjalnie niebezpiecznej biblioteki do kodu produkcyjnego aplikacji – poprzez specjalne mechanizmy pewne zmiany po prostu nigdy nie znajdą się w środowisku, w którym mogłyby wyrządzić spore szkody – wnieść ogromne ryzyko ograniczenia wysokiej dostępności usług dla klientów na całym świecie.
Jeśli chcecie dowiedzieć się więcej o mechanizmach Software Composition Analysis, zapraszam do zapoznania się z podlinkowanymi materiałami. A może porozmawiamy o tym na naszej najbliższej rozmowie rekrutacyjnej?
Źródła:
